























W kolejnej odsłonie DISEN’a zaprezentuję praktyczne zastosowanie silnika skryptów w rozwiązaniu konkretnego wdrożeniowego problemu. Tytułowi bohaterzy: Wspaniały (luźne tłumaczenie Groovy) oraz Lucyna (bardzo potoczna nazwa biblioteki Apache Lucene) stają ramię w ramię w celu rozwiązania problemu szybkiego i wygodnego wyszukiwania zbiorów danych o znacznym rozmiarze oraz o skomplikowanej strukturze.
Problem: Przy niektórych wdrożeniach systemu VERTO spotykamy się z jednej strony z ogromnymi zbiorami danych np. miliony towarów, czy kontrahentów, a z drugiej strony z wymaganiem szybkiego i wygodnego ich przeszukiwania. Sprawę komplikuje fakt, że sam sposób wyszukiwania jest jakby to powiedzieć „technicznie niebanalny”, mianowicie wyszukiwanie ma nie zwracać uwagi na wielkość znaków, szukać wewnątrz ciągów, słów w dowolnej kolejności, całych słów jak ich początków, przeszukiwać pola MEMO, wartości cech, czy inne kolumny oddalone w znaczny sposób od zbioru głównego, wszystko oczywiście przy niewielkim obciążeniu systemu i milisekundowym czasie wykonania.
Na platformie NEXT dedykowanym rozwiązaniem dla tej klasy problemów od niedawna jest wyszukiwanie pełnotekstowe oparte o bibliotekę Lucene a dokładniej o platformę indeksowania i wyszukiwania SOLR, która w backend’zie używa właśnie Lucene. Podstawowy schemat zakłada, że wyszukiwanie odbywa się wg ww. założeń np. ciąg „Streamsoft spółka jawna Systemy Informatyczne” znajdziemy, podając: „streamsoft” lub „spółka” lub „strea” lub „jaw” lub „sp jaw”, ale także „jaw sp”.
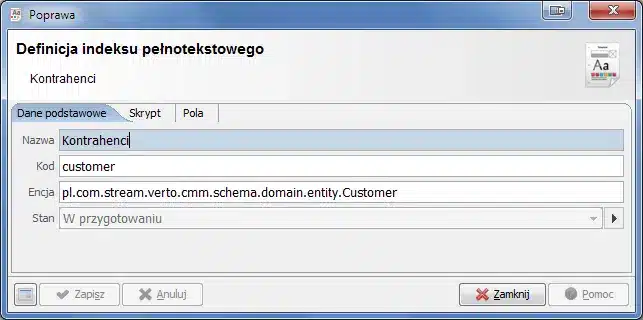
Czynności, które należy wykonać, aby uruchomić wyszukiwanie pełnotekstowe, rozpoczynamy od instalacji i konfiguracji SOLR’a. W Verto natomiast należy podać w konfiguracji systemu wskazanie na adres, pod jakim SOLR wystawia swoje usługi. Kolejnym krokiem jest zdefiniowanie samego indeksu. Za przykład posłuży nam indeks do wyszukiwania kontrahentów. Podstawowe dane indeksu to:
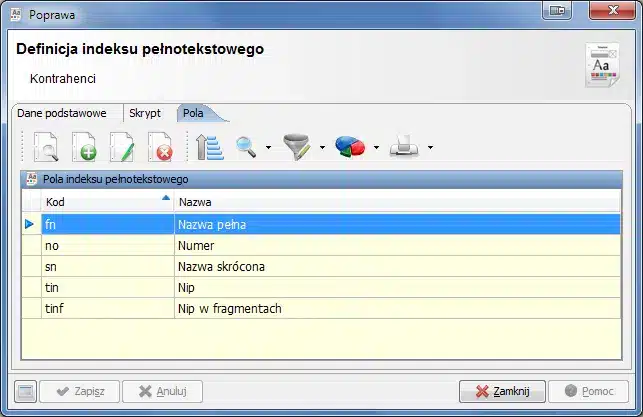
Oraz pola indeksu:
Miejscem gdzie DISEN spotyka się z Lucene, jest skrypt odpowiedzialny za tworzenie elementów składowych indeksu, czyli jego dokumentów, zobaczmy schemat działania takiego skryptu:
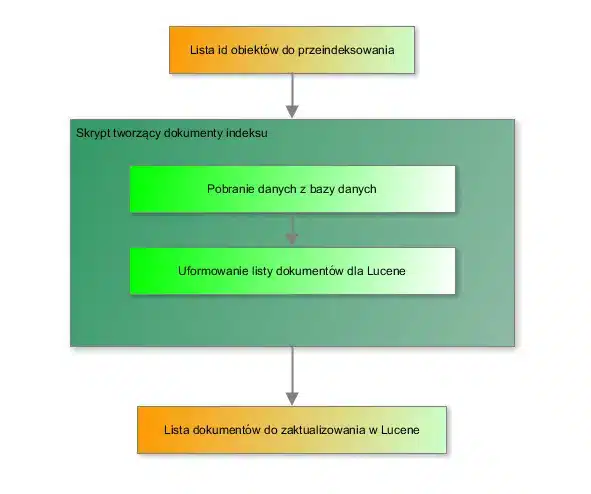
Konstrukcję dokumentu:
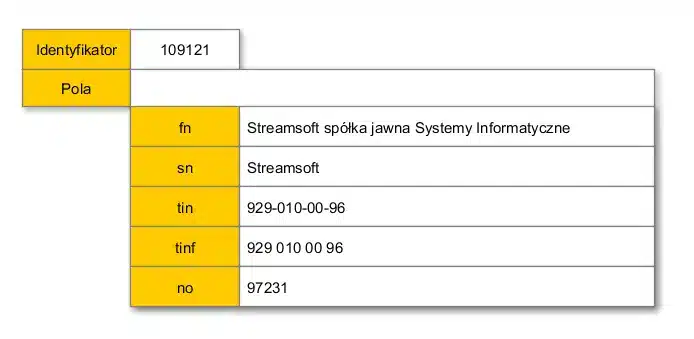
Przykładowy skrypt:
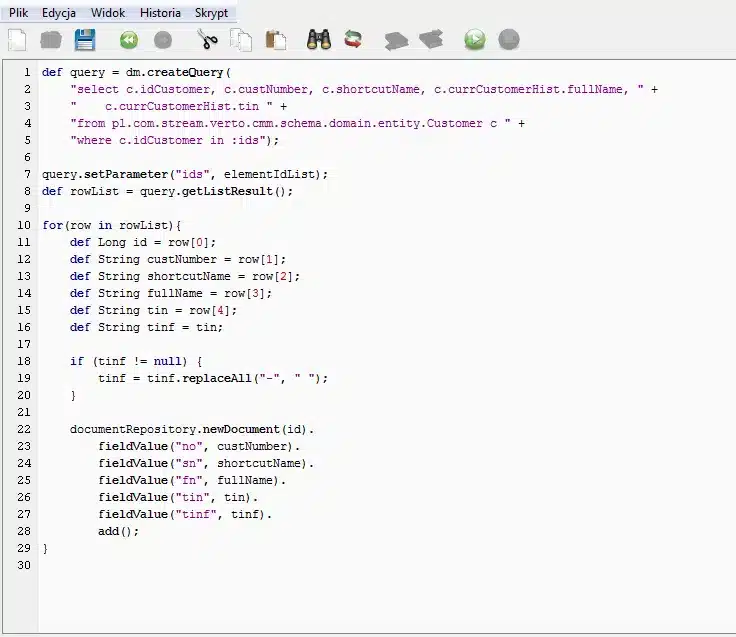
Elastyczność, jaką daje nam przeniesienie strategii budowania dokumentu dla indeksu do skryptu dostępnego do modyfikacji w trybie wdrożeniowym, jest ogromna. Mamy pełną dowolność w zakresie pobrania danych do dokumentu, ograniczoną praktycznie tylko i wyłącznie możliwością napisania odpowiedniego zapytania. Mamy także pełną elastyczność w ułożeniu tych danych w samym dokumencie. Tak jak w przykładzie widać, że pole zawierające NIP, trafia do indeksu, raz jako całość z kreskami umożliwiając wyszukiwanie w rodzaju 927-, 929-010, ale także pozbawione kresek zastąpionych spacjami co pozwoli szukać po wewnętrznych numerach NIP np. 010. Dodam, że możliwości są większe niż pokazane w przykładzie, można rozbudować zapytanie o pobieranie wartości z uwag, ostrzeżeń (pola typu MEMO), a także wybranych wartości cech, można dowolnie formatować i korygować zawartość pól indeksu uzyskując różne efekty wyszukiwania.
W ostatnim etapie należy indeks uruchomić oraz ustawić w opcji „Kontrahenci”, w konfiguracji wyszukiwania, metodę wyszukiwania opartą o zdefiniowany właśnie indeks:
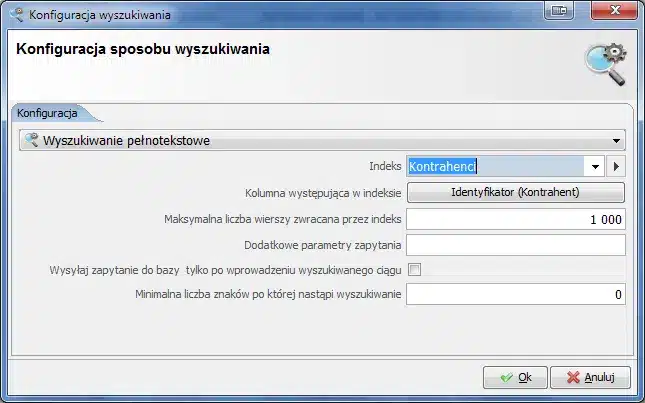
Następnie cieszyć się szybkim i wygodnym wyszukiwaniem w naszej ogromnej bazie kontrahentów.

Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania
Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania