


























W ostatnich tygodniach uczestniczę w pracach zespołu analitycznego, którego zadaniem jest transformacja kodu biznesowego aplikacji z postaci skryptu transakcyjnego (transaction script) do postaci bardziej zgodnej z OOP. Od razu muszę zaznaczyć, że „transaction script” nie jest generalnie i zawsze antywzorcem. Wręcz przeciwnie, w wielu prostych przypadkach jest to podejście wystarczające (good enough) i optymalne. Jednak w pewnych kontekstach, potencjalne wady, które opisałem w poprzednim wpisie, powodują znaczne problemy przy nieuzasadnionym jego zastosowaniu. Jaka jest istota skryptu transakcyjnego? W tym podejściu zakładamy, że algorytm to ciąg instrukcji, gdzie kolejność ich wywoływania jest klasyczną kolejnością wykonywania linii, linia po linii, w najbardziej naturalny dla programisty sposób. Co może być złego w wykonywaniu kodu linia po linii? Wydaje się, że nic. Ale przypomnijmy sobie jak dosyć już dawno udało się nam zdeprecjonować podobnie oczywisty operator „new”, jako zawsze najlepszą formę tworzenia instancji czy komponentów. Przez długi czas „new” wydawało się tak bardzo naturalne i niezagrożone. A jednak, wzorzec fabryki, metody fabrykującej, budowniczego czy w końcu wstrzykiwanie zależności pokazały słabości „new” w wielu przypadkach (Ewolucja w kodzie). Z pisaniem i wykonywaniem kolejno linii pod linią jest tak samo. Choć można się mocno zdziwić, jednak to nie zawsze się sprawdza.
Częstym źródłem problemów i pomyłek wokół „transaction script” jest niezrozumienie zasad programowania obiektowego. Zakładanie, że klasy to wyłącznie pojemniki na kod, że metoda to taka procedura ale umieszczona w klasie z dostępem do wspólnych zmiennych „globalnych” w zakresie instancji klasy. Jeżeli tak myślimy to prawdopodobnie nie programujemy obiektowo a proceduralnie, bo właśnie z takiego paradygmatu wywodzi się powyższe myślenie. Na poniższym przykładzie, widzimy kod będący skryptem transakcyjnym:

Zmierzając w kierunku modelu obiektowego, kod ten można by z powodzeniem przetworzyć na zbiór lub graf osobnych, autonomicznych bytów obiektowych. Byty te, zależnie od założeń architektów, mgły by przyjąć różną postać, jedną z nich mogłaby być postać reguł biznesowych. W poprzednim wpisie (Kodzik) opisywałem już taką transformację z jej zaletami i wadami. Tu na początku prawdopodobnie powstał by wspólny interfejs reguły:
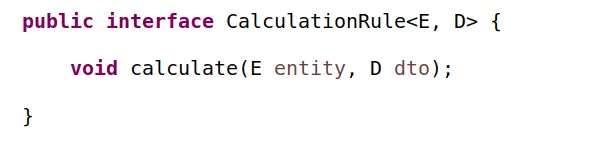
oraz seria reguł, podobnych do:
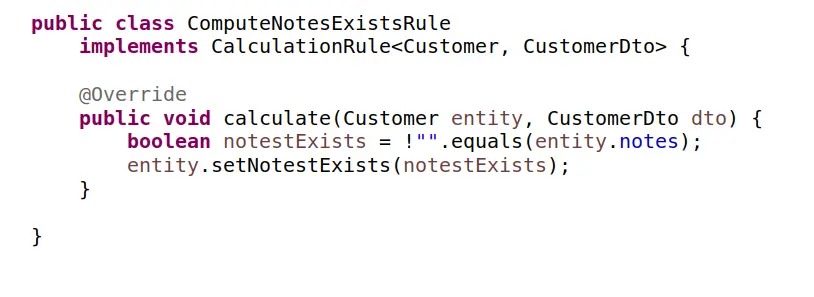
i można by na tym skończyć, gdyby nie jeden ważny szczegół. Autor skryptu transakcyjnego, który jest bazą naszych rozważań, oprócz zbioru kalkulacji (wywołań metod), które zawarł w swoim algorytmie, umieścił je jeszcze w pewnej kolejności. Czy to zamierzone, czy przypadkowe? Czy ta kolejność ma jakieś znaczenie? Niestety nie mamy szans na uzyskanie odpowiedzi patrząc na sam kod tej metody. Aby to ustalić, musimy analizować poszczególne implementacje. Dużo pracy. A gdyby z czasem trzeba było dodać nową regułę (metodę), to gdzie ją dopisać? Na koniec? A gdyby zaszła potrzeba zmiany implementacji jakiejś reguły to czy nie musimy zastanowić się czy nie wpłynie to na inne reguły? Znowu musimy analizować poszczególne implementacje. Znowu dużo pracy. Wygląda na to, że umieszczenie wywołań tych poszczególnych metod jedna pod drugą, bez jakieś wyraźnej przyczyny, jest dla nas kłopotliwe. Wg mnie jest to ogromny problem, którego zazwyczaj nie dostrzegamy i nie doceniamy.
Zastanówmy się jak moglibyśmy ustalić porządek w którym mają być wykonywane nasze reguły. Z pomysłów które przychodzą mi do głowy na szybko:
- zostawić to tak jak jest, po prostu czasem kolejność nie ma znaczenia, więc może być przypadkowa, a to że ją narzucamy jest tylko niemającym znaczenia faktem,
- uznać, że nie można się opierać na kolejności, będzie ona losowa, reguły muszą być autonomiczne i odporne na zmianę kolejności,
- nakazać zawsze określać kolejność w jakiś ustalony sposób, a do tego dwie reguły nie mogą mieć tego samego „lp”
- …
Można by długo jeszcze szukać odpowiedniego sposobu. Ja w takich sytuacjach lubię się posłużyć (choćby spróbować) wzorcem mentalnym
„break on through”
Jak coś nie idzie i jest ciężkie, skomplikowane, po prostu tego nie rób, postaraj się znaleźć takie rozwiązanie, w którym to się będzie robić samo albo wręcz nie będzie się robić wcale. Idąc w myślenie zgodne z tą zasadą, zacznijmy od zastanowienia się jak wyglądałby ideał, np.:
- kolejność, kiedy trzeba, była taka jak trzeba
- kolejność, kiedy nie trzeba, była losowa
- nikt nie musiał się nią zajmować
- algorytm nigdy nie wykona się w „złej” kolejności
- algorytm zawsze wykryje ewentualne niespójności w zbiorze reguł i je elegancko zaraportuje
Aby to uzyskać możemy posłużyć się wzorcem „sort over requirements”. Do naszej reguły dodamy, dwie metody:

a implementacja przykładowej reguły mogłaby wyglądać tak:

Nasz reguła, oprócz swojej głównej funkcji obliczania, robi jeszcze jedną ważną rzecz, deklaruje czego potrzebuje a co jest w stanie dostarczyć. Co się teraz stało z naszym kodem? Zwróćmy uwagę, że:
- autorzy reguł nie myślą o kolejności, skupiają się tylko na tym co wiedzą, czyli jak liczyć, na czym to opierać i co jest efektem obliczeń,
- zbierając teraz wszystkie reguły, mamy pełną wiedzę, która czego potrzebuje a to pozwala ustalić w jakiej kolejności należy je uruchamiać
- wiemy, że jako pierwsze uruchomimy te reguły, które nie mają żadnych wymagań wstępnych, oczywiście uruchomimy je w kolejności losowej
- wiem także, że zbiór reguł musi być spójny, skoro jakaś reguła potrzebuje faktu „x” to jakaś inna musi taki fakt dostarczać
- umiemy wykryć zależności cykliczne i zgłosić veto jak je wykryjemy
- możemy wykryć sytuacje gdy więcej niż jedna reguła dostarcza tego samego faktu, co mogło by doprowadzić do niejednoznaczności,
- możemy realizować część reguł równolegle, mamy wiedzę które się do tego nadają,
- …itd.
Jednym słowem zwycięstwo zarządzalnej złożoności nad sztywnym uproszczeniem. Będąc spostrzegawczym można jednak dostrzec w powyższym kodzie pewien problem. Deklarowanie faktów polega na podawaniu ciągów znaków, co jak wiemy jest podatne na błędy, literówki. Pokazujemy to tyko jako pewne uproszczenie na potrzeby przykładu. Można założyć, że docelowo kontekst obliczeniowy czy logiczny na którym operujemy mógłby nam dostarczać wspólnego i spójnego zbioru faktów, rozwiązując elegancko problem.
Na koniec jak zawsze nie mogę nie napisać, że stosowanie „sort over requirements” (czy podobnych wzorców) zawsze należy przemyśleć, czy na pewno w naszym kontekście potrzeba aż tak silnego wzorca, aż tak rozbudowanej architektury.

Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania
Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania