


























Kiedy ktoś spoza środowiska programistów pyta mnie ile słów trzeba poznać, aby móc programować w jakimś języku, wiem, że gdy zgodnie z prawdą powiem, że jest ich kilkanaście lub niewiele więcej, wywołam u rozmówcy błędne wrażenie jakoby to programowanie było bardzo prostą profesją. Nie łatwo jest komukolwiek wytłumaczyć ogromną złożoność dowolnie wybranej programistycznej platformy językowej. Paradygmaty, narzędzia, biblioteki, frameworki, szkielety, wzorce, antywzorce, idee, reguły projektowe, i w końcu to co najtrudniejsze, myślenie w pewien odmienny, abstrakcyjny i skrzywiony do granic utraty kontaktu z realnością sposób. To niewiarygodnych rozmiarów stos, który trzeba przyswoić. To wszystko razem, wyczytane i przemyślane, przećwiczone i wciśnięte w broniącą się przed tym świadomość, to jest właśnie to. To mniej więcej tyle co być programistą.
Dodać należy, iż samo dojście do tego niełatwego punktu, kiedy w końcu po latach trudu się go osiągnie, nie gwarantuje tak zwanego sukcesu. Nawet jeżeli spełniamy już powyższą definicję, okazuje się, że czasem tworzymy kod „dobry” a czasem kod „zły”, a zmierzając bliżej prawdy to co powstaje, jest zazwyczaj gdzieś pomiędzy tymi dwoma skrajnościami. Dlaczego? Wg mnie dlatego, że pomimo wszystko, programowanie do końca pozostaje zajęciem silnie twórczym, gdzie jest wciąż dużo miejsca na znajdowanie wielu dróg do rozwiązania wielu problemów, a także wielu dróg do rozwiązania tych samych problemów, i w końcu – co najbogatsze w konsekwencjach – brakuje sprawdzonych dróg do rozwiązywania wielu częstych problemów. W konsekwencji tego, zazwyczaj trudno ustalić z jakąkolwiek pewnością, które rozwiązanie jest optymalne lub choć mu bliskie. Aby to zobrazować spójrzmy na fragment pewnego „kodziku”:

jak dobry jest ten kod? Omówmy najpierw zalety. Jest ko kod prosty, niespełna 30 linii, poprawne nazwy, komentarze wyjaśniające w zasadzie wszystko. Widać dbałość o kilka technicznych aspektów. A wady?
- (1) Ten kod praktycznie nie nadaje się do testowania jednostkowego, są w nim odwołania do zewnętrznych zasobów DAO i CFG, oznacza to potencjalne problemy z czystym kodem testów, najpewniej będzie trzeba „stabować” czy „mokować”, o ile się w ogóle da.
- (2) Ten kod praktycznie nie nadaje się do testowania jednostkowego bo robi wiele rzeczy naraz, a to będzie dawać eksplozję kombinatoryczną przypadków testowych, w zasadzie uniemożliwiając napisanie logicznych testów.
- (3) Ten kod narusza podstawową zasadę projektową „bądź gotowy na zmiany ale nie poprzez modyfikacje”. Przy zmianie dowolnej reguły, albo dodaniu nowej, będzie trzeba zmieniać dokładnie ten kod.
- (4) Ten kod ma niską wartość spójności (cohesion), poszczególne fragmenty kodu są ze sobą bardzo słabo logicznie związane, zajmują się ustalaniem stanów, ale z różnych zakresów merytorycznych (stąd też problemy z eksplozją kombinatoryczną przypadków).
- (5) Ten kod musi posiłkować się używaniem komentarzy, bo inaczej nie byłby wystarczająco zrozumiały.
- (6) Ten kod może potencjalnie opierać się na kolejności linii, co niesie ryzyko podczas przyszłych zmian czy refaktorów.
- (7) Treść tej metody zajmuje dużo linii (prezentujemy fragment) i będzie się wydłużać, co potencjalnie będzie rodzić problemy ze złożonością.
- (8) Ten kod zawiera dziwną regułę (ostatnia), która w zasadzie jest złączeniem dwóch osobnych reguł, najpewniej z oszczędności linijek kodu, problem ten widać już w samym komentarzu.
To nie jest pełna lista, ale postanowiłem przy tym pozostać. Jak zatem poprawić ten kod? Zapytany o to jeden z programistów (hipotetyczny średnio zaawansowany junior) mógłby zaproponować coś takiego:

Czy ten kod jest lepszy? Poprawiamy lekko (3), minimalnie lepiej jest w (5), minimalnie lepiej w (6), naprawiono (7) i (8), a wszystko to kosztem zdecydowanie większej ilości linii i nie da się ukryć wzrostem złożoności. Warto było ponieść taki koszt? Moim zdaniem tak. Autor zmiany zrobił minimalny krok naprzód. Może za mały, pewnie może nawet nie do końca w dobrym kierunku, może to być ślepa uliczka. Dużo tych „może”. Ale właśnie będąc o krok dalej można dostrzec więcej i jest szansa na rozwój i dalsze usprawnienia.
Podejście drugie, wyobraźmy sobie kilkuosobowy zespół, złożony z osób o różnym doświadczeniu, po kilku godzinach prac zespół ten mógłby zgodnie zaproponować coś takiego:
na początek:
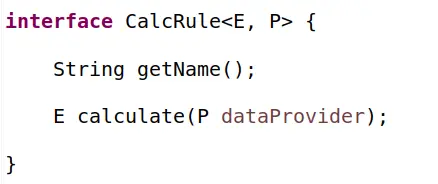
i dla każdej reguły coś na kształt:
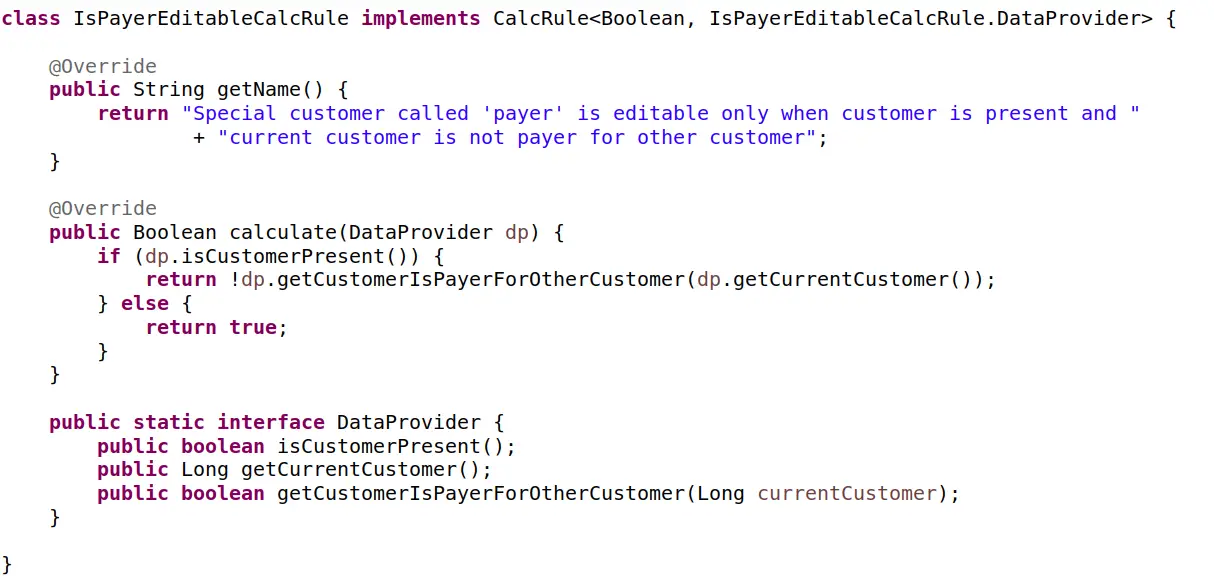
to nie koniec, bo jeszcze:
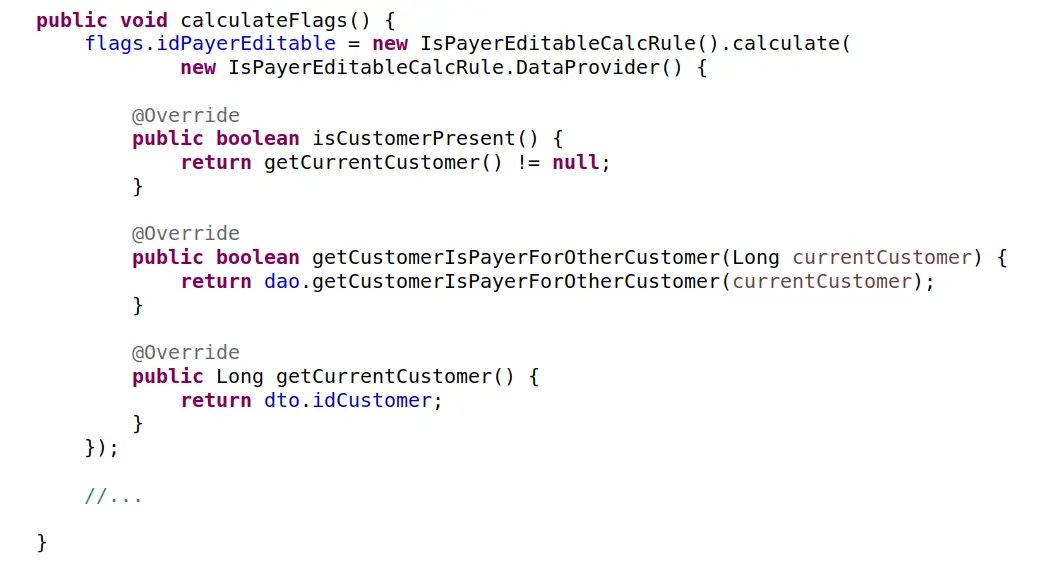
Czy ten kod jest lepszy? Nie da się ukryć, naprawiamy za jednym razem wszystkie problemy. Uff. Jest jeszcze więcej możliwości i korzyści. Powstał nowy byt, reguła kalkulacji stanu! Choć nowy i zaskakująco prosty, wydaje się być bytem rzeczywistym. Można zgodzić się, że to porządkuje i także otwiera kolejne możliwości, choć to już naprawdę dużo architektury. A jaki jest koszt tej operacji? Policzcie ilość klas, interfejsów, ilość metod i linii. Bardzo mocno wzrosła złożoność. W dodatku pewne niewygodne kwestie „wypchano” do dostawcy danych dla reguły, którego to dostawcę trzeba w takim razie także przetestować, czy już nie :)?
Jak znaleźć odpowiedź na pytanie, gdzie znajduje się optimum? Gdzie zatrzymać się na drodze do optymalnej architektury tak aby nie przesadzić ze złożonością? To ogromnie ważne pytania, kluczowe dla każdej aplikacji, systemu i zespołu. Nie mam przepisu na prostą i łatwą odpowiedź. Ale jednego jestem pewien. Zawsze ale to zawsze, podejmujcie takie decyzje świadomie. Trzeba wiedzieć jakie są możliwości, jakie są możliwe rozwiązania, architektury. Znajcie ich wady, zalety, koszty, ryzyka. Jak już to będziecie mieć, pozostaje zaufać sobie (a zdecydowanie lepie swojemu zespołowi) i starać podjąć się optymalną na stan wiedzy w danej chwili decyzję. Pozostaje jeszcze otwarta kwestia złożoności. Jak ją traktować? Czy zawsze jako koszt? Znana jest klasyfikacja złożoności na dwie kategorie:
Złożoność esencjonalna i wytworzona
Esencjonalna to taka, która po prostu istnieje, z jaką się stykamy, jaką musimy przyjąć, bo właśnie taka jest rzeczywistość w zakresie problemu którym się zajmujemy. Wytworzona (zwana czasem przypadkową) to ta którą sami generujemy, taka, która nie jest konieczna, ale wprowadzamy ją, bo ze względu na nasze słabości inaczej nie umiemy. Esencjonalną powinniśmy akceptować a wytworzonej unikać. Czy nasze zespołowo wykombinowane powyższe „reguły obliczania stanów” istnieją naprawdę, czy to wymysł? Na to pytanie odpowiedzieć musicie sobie sami.

Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania
Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania