


























Przyglądając się ewolucji kodu źródłowego programów nie sposób nie odnieść wrażenia, że na przestrzeni lat staje się on bardziej naturalny. Naturalny w takim znaczeniu, że bardziej bliski naszemu, ludzkiemu sposobowi myślenia. Ale czy jest tak na pewno? Parafrazując klasyka „Wcale nie jestem pewien, a wręcz przeciwnie, mam poważne wątpliwości”. Kierunek w którym zmierzamy zaczyna zbliżać nas do kręcenia się w kółko, ale nie w sposób pozbawiony sensu, bardziej taki, który już niedługo może zmienić (w zaskakujący nas sposób) reguły gry. Aby tego dowieść zobaczmy jak to się zmieniało od samego początku, od kiedy możemy sięgnąć wikipedią.
Na początku wiadomo, było zero i jeden. Z tej pierwotnej, binarnej zupy wyłonił się kod maszynowy. Kod zgodny z koncepcją maszyny Turinga, kod taki może wyglądać np. tak:

Jak wdać, nie jest on w żaden sposób dla kogokolwiek zrozumiały i naturalny. Zaraz za nim pojawił się Asembler:

Jest lepiej, ale dalej niewielu z tego cokolwiek zrozumie. Jako pierwszy język wysokopoziomowy w okolicach 1945 roku pojawił się Plankalkül. Nikt go nie pamięta, nikt nie zna, tym bardziej jego składnia:
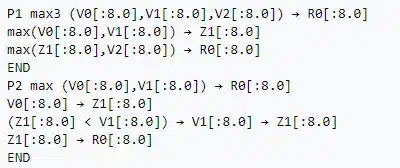
nic nam nie mówi i naturalna dla kogokolwiek nie jest. Przelatując ze trzydzieści lat do przodu (pomijając ogromny zbiór języków, i żeby nie było, pomijam je, ale szanuję) otrzymaliśmy w końcu język C. W 1978 opublikowano jego pierwszą specyfikację. No to był znaczny postęp, wystarczy spojrzeć:

Pojawiają się tu słowa, które znamy z naszej mowy potocznej. Nie jest zaskoczeniem, że „switch”, „case”, „break” czy „default” to zwykłe słowa wyjęte z języka angielskiego. Do tego naprawdę robią one coś, co jest bardzo zbieżne z tym co znaczą w języku naturalnym. Mamy początek lat osiemdziesiątych i tak bardzo czytelny kod, czujemy już duży komfort. Przelatując jeszcze kilkadziesiąt lat w nowoczesność dostajemy:
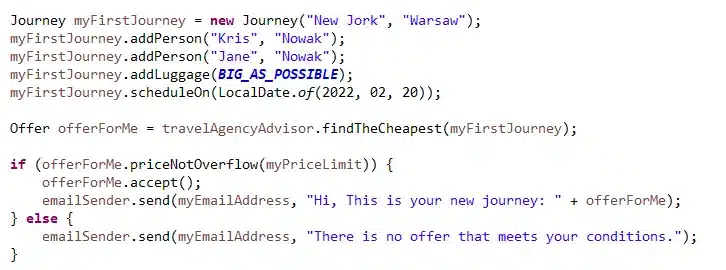
I tu zrobiło się ciekawie. Kto rozumie ten kod? Dla kogo jest on naturalny? Nie przesadzając, dla każdej osoby o dowolnym zawodzie, dowolnym wykształceniu, wystarczy aby ta osoba znała język angielski i potrafiła czytać i pisać. Tak to jest w pełni naturalny kod. Dostaliśmy takie możliwości już dosyć dawno. W 1980 pojawił się Smalltalk i zmienił myślenie o tym jak powinniśmy programować komputery. Wprowadził on szeroko na koderskie salony koncepcję OOP (Object Oriented Programming), pojawiła się szansa ucieczki od dziwnych niezrozumiałych symboli do prawie prozy. Programy można było pisać jak zbiór historyjek które mają realizować. Kolejne języki nie zmieniały w zasadzie nic istotnego, Java (z przykładu), C#, Python i inne języki, realizują cel w podobny, bardziej lub mniej skuteczny sposób. Jedynie żwawy pochód podejścia deklaratywnego (SQL, XML, HTML, CSS, …) w pewien sposób i w pewnych dziedzinach dostarczył wyraźnej jakościowej zmiany. W zasadzie mógłby to być koniec historii. Jednak ta nie lubi prostych czy banalnych zakończeń.
Od dawna, od bardzo dawna dostrzegaliśmy zaskakującą różnicę pomiędzy tym jak działa nasz mózg (naturalny) a działaniem komputerów (nienaturalny). Nasz mózg nie jest maszyną Turinga, nie przetwarza strumienia instrukcji, nie używa także zera i jedynki, a raczej operuje na sygnałach ciągłych (o dowolnej ilości wartości pośrednich pomiędzy 0 i 1). Zaskakujące jest to tym bardziej, że nasze mózgi w wielu dziedzinach odnoszą ogromne sukcesy. Potrafimy prowadzić samochód, rozumieć mowę, utrzymać równowagę, pisać wiersze, grać w szachy, … uff, a u konkurencji z tymi „if”, „return” itd. nie jest zbyt dobrze. Maszyna Turinga w naszych komputerach, programowana w językach wydawałoby się naturalnych, nie może osiągnąć tego co nasze mózgi i mózgi wszystkich innych mniejszych stworzeń osiągały już dziesiątki tysięcy lat temu. Po raz któryś zapytam, czy na pewno? Zobaczmy ten kod:
Co to jest? To jest zrzut z „mózgu” sieci neuronowej. Sieci neuronowej czyli fundamentu tak zwanej „sztucznej inteligencji”, choć ta nazwa jest tak niepasująca do rzeczywistości jako to tylko możliwe. Sieci neuronowej, czyli próby symulacji działania naszego mózgu na maszynie Turinga. Próby, jak już powszechnie wiemy, dosyć udanej. Co robi powyższy kod? Nie ma „kozaka”, który by to wiedział. Dodatkowo powiem, że znalezienie tego „kodu” gdziekolwiek w sieci nie jest łatwe czy wręcz możliwe. Trzeba sobie wyuczyć sieć, a potem zrzucić jej stan np. w powyższej postaci na konsolę czy do pliku. Przyczyna jest prosta, nikt tego nie ogląda. Są to wagi z wejść neuronów ubrane w macierze liczb rzeczywistych. Analiza tych liczb nie ma sensu. Tworzy się sieć, ustalając jej topologię, następnie „uczy” się ją tego, co ma potem umieć i jak się uda to „powstają” czy „układają się” w niej te liczby tak, że to po prostu działa w efekcie realizując zamierzony cel z minimalnym, choć wciąż nie zerowym błędem.
Czy ten kod jest zatem naturalny? Skoro jest podobny do tego co natura przez miliony lat ewolucji wykombinowała, to nie można powiedzieć, że nie. Można wręcz stwierdzić, że nie ma nic bardziej naturalnego, jest tu ogromna zgodność z biologicznym mózgiem złożonym z neuronów. Ale czy to potrafi już zrealizować wyżej podaną listę „prowadzić samochód, rozumieć mowę, utrzymać równowagę, pisać wiersze, grać w szachy”. Tak potrafi i to doskonale, tak doskonale, że już teraz, lub za małą chwilę, we wszystkich tych dziedzinach przegoni (z wierszami można dyskutować, czytałem je i wolę Szymborską) nasze galarety schowane w czaszce na tyle, że zniknie sens używania ich do tego.
Jakoś mnie to nie martwi. Czuję, że jest to całkiem naturalna (i to dosłownie) kolej wydarzeń. Ale, gdyby dołożyć do tej listy „tworzenie kodu”, to już niejeden rasowy IT’men może poczuć krople potu na kręgosłupie. No to Panowie i Panie, mam niestety smutną/wspaniałą wiadomość, to się też dzieje, oczywiście jest to dopiero początek, ale wygląda na to, że z tej drogi nie ma powrotu. Tu ciekawostka, skąd brane są dane do nauki sieci neuronowych, które miały by tworzyć za nas kod? Wiemy przecież, że duża ilość i jakość danych uczących jest kluczowa i decydująca dla AI. Na dzień dzisiejszy sieci uczą się analizując kod opensource i każdy inny powszechnie dostępny np. w publicznych repo na GitHub. Co oznacza, że danych do nauki nie brakuje, choć są kontrowersje co do jego jakości. Aby tego doświadczyć „na własnej skórze” polecam chwilę poświęcić na zapoznanie się z możliwościami i działaniem GitHub Copilot.
Podsumowując, naturalnie, na koniec, wszystkim pasjonatom programowania (sobie też) życzę góry optymizmu co do naszej przyszłości.

Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania
Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania