


























Relacyjne bazy danych opierają się na założeniu, że dane które przetwarzamy posiadają strukturę dającą się całkiem optymalnie reprezentować w postaci modelu relacyjnego. Model taki zakłada, że dane można podzielić na osobne zbiory danych (tabele), związane ze sobą jakąś formą relacji. Model taki można poddać skutecznemu procesowi normalizacji i dalej de-normalizacji a działając tak iteracyjnie dojść do optymalnej (dla naszego przypadku) postaci. Relacje pomiędzy tabelami to gównie:
1:N, „jeden do en” czyli np. jedno zamówienie „posiada”, „zawiera”, „odnosi się do” wielu (do dowolnej liczby) pozycji zamówienia, a każda pozycja zamówienia „należy” do dokładnie jednego zamówienia.
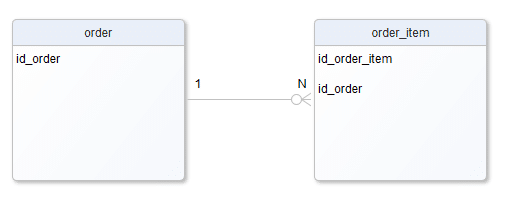
N:1, „en do jeden”, Patrząc z drugiej strony na relację 1:N (od strony pozycji zamówienia) można powiedzieć, że relacja z zamówieniem to N:1 i to prawda, 1:N i N:1 to ta sama relacja tylko widziana z innej strony.
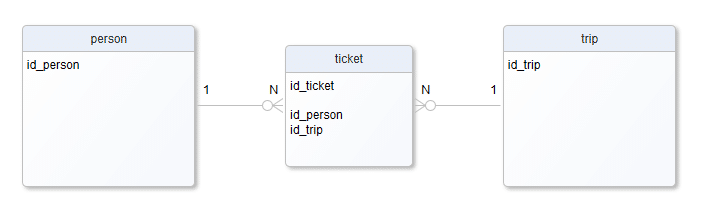
N:N, „en do en” czyli np. osoba może „uczestniczyć” w wielu wycieczkach a w każdej wycieczce może „uczestniczyć” wiele osób. Relacja taka, choć bardzo częsta, nie może być reprezentowana wprost w typowym fizycznym modelu bazy, dekomponuje się ją zazwyczaj do dodatkowej tabeli i dwóch relacji 1:N.
1:1, „jeden do jeden” czyli np. … no właśnie, zna ktoś sensowny przykład relacji 1:1?, ale nie taki sztuczny, np. podział jednej tabeli na dwie, ze względów optymalizacyjnych czy technicznych … Coś tam pewnie da się znaleźć, np. pracownik – operator systemu, pracownik może być jakimś operatorem systemu (nie musi), a operator systemu wiadomo jakim dokładnie jest pracownikiem. Tu trzeba zaznaczyć, że aby taką relację zrealizować w standardowy sposób musimy się zdecydować, kto będzie właścicielem relacji. Czy to operator systemu będzie miał wskazanie na pracownika czy pracownik na operatora systemu. Na coś trzeba się zdecydować. Zakładając, że wybierzemy pierwszą wersję, otrzymujemy:
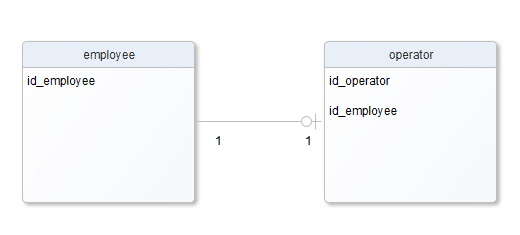
Jak się bliżej przypatrzyć, to widać pewne podobieństwo, gdyby to była relacja 1:N to wyglądało by to tak:
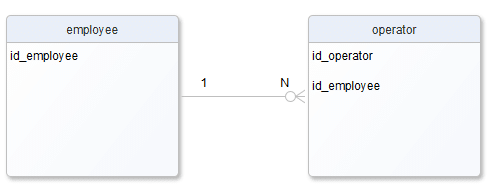
Spójrzmy na tabele, mają dokładnie te same kolumny jak na poprzednim diagramie, no cóż, relacja 1:1 jest szczególnym przypadkiem relacji 1:N gdzie N==1, i z punktu widzenia relacji w bazie danych (foreign key), czy późniejszych instrukcji złączeń JOIN w zapytaniach SQL, nie ma pomiędzy nimi znaczącej różnicy. Jedyną zmianą jest dodanie ograniczenia unikalności na kolumnę „id_employee” w tabeli „operator”, a i tak nie zawsze się to robi.
Wniosek który z tych rozważań wynika jest dosyć prosty, tak naprawdę, z punktu widzenia modelu fizycznego bazy, mamy jeden rodzaj relacji 1:N, po prostu pewne tabele mogą mieć wskazania na wiersze winnych tabelach i to wszystko, nic poza tym. Rzeczywistość architekta baz danych relacyjnych jest zatem dosyć nudna i niepokojąco zbliża się do antywzorca „golden hammer”.Przeanalizujmy zatem potencjalne wady „wrzucania ajdika zawsze i tylko” oraz poszukajmy innych metod modelowania i przechowywania danych w bazach. Z wad klasycznych relacji należy wymienić:
Zwiększanie zależności
Z punktu widzenia aplikacji modułowych, a takie uważamy często za lepsze niż monolityczne (pominę argumentację), wadą podstawową modelu relacyjnego jest zwiększanie zależności pomiędzy tabelami w bazie danych, szczególnie wtedy gdy należą one do innych kontekstów. Z punktu widzenia kontekstu zamówienia, dziwne jest to, że aby wiedzieć jakie mam pozycje muszę wiedzieć jak nazywa się „jakaś tam inna” tabela, która zawiera dane „moich” pozycji, muszę czytać dane z tej innej tabeli wiedząc, że jej architekt w pewnej kolumnie przewidział zapamiętywanie mojego ID, dodatkowo ten architekt utworzył więzy integralności które powodują, że ja mam ograniczone pole działania, np. nie mogę się usunąć, bo jakaś magiczna reguła (foreign key w tamtej tabeli, ja jej nie zdefiniowałem a ona mnie ogranicza) mówi „veto” gdy stwierdzi u siebie istnienie wierszy które zawierają wskazanie do mojego wiersza. Uff, zależę od czegoś na co nie mam wpływu. Bardzo dziwne się czuję jak zrozumiem, że każdy architekt może w dowolnej tabeli umieścić odwołanie do mojej tabeli bez mojej wiedzy i mnie w ten sposób ograniczać (pomijam tu fizyczne ograniczenia wynikające z uprawnień do schematów i tabel).
Zwiększanie złożoności
Aby odczytać pełne dane zamówienia, zmuszony jestem do czytania danych z tabeli zamówienia oraz dodatkowo z tabeli pozycji zamówienia. Niby nic strasznego, a jednak, gdy nie tylko dane o pozycjach ale i o nabywcy, adresie dostawy, kurierze, liście przewozowym, itd. znajdują się w innych tabelach, uff, mam wtedy trudne zadanie wykonania bardzo wielu odczytów i to z bardzo wielu różnych tabel, muszę znać i rozumieć ich strukturę, mój (już nie tylko mój) model danych staje się ogromnie złożony, trudny do zrozumienia a także „kruchy”, łatwo go zepsuć w trakcie zmian rozwojowych, łatwo się pomylić przy odczycie czy zapisie danych.
Degradacja wydajności
Wspomniana wyżej konieczność czytania danych z wielu tabel wymaga wysłania do serwera wielu poleceń SQL lub/i poleceń z wieloma klauzulami JOIN, po stronie serwera są to zadania wysoce kosztowne do zrealizowania. I tak aby np. odczytać wszystkie pozycje zamówienia, trzeba wczytać do bufora bazy danych drzewo indeksu (zakładamy optymistycznie że taki jest) który zawiera wartości kolumny „id_order” w tabeli „order_item”. Indeks ten, po dłuższym czasie funkcjonowania systemu, może być naprawdę duży i nie zawsze będzie czekał w gotowości w buforze bazy co wymusi jego okresowy odczyt z dysku. Odczyt z dysku da w konsekwencji duże opóźnienie, a jak już się indeks wczyta, to zostanie przeszukany (to szybka operacja), a potem będzie trzeba załadować wszystkie strony tabeli z pliku na dysku, na które wskazał nam indeks, a to może także potrwać, następnie w tych stronach odszukać wiersze, wszystko zebrać i odesłać. Podsumowując, nie jest to mało pracy do wykonania, a trzeba to wykonać n razy bo czytamy nie tylko pozycje ale także inne dane. Charakterystyczne jest to, że jest to zazwyczaj dużo małych porcji danych, czytanych z wielu dużych źródeł.
Przytłoczeni powyższymi wadami klasycznych relacji 1:N, zastanówmy się jakie mamy inne możliwości modelowania naszych danych. I tak:
Zawłaszczenie relacji
Pozostając przy relacyjnych bazach danych, w technice „zawłaszczania relacji” zakładamy, że to obiekt nadrzędny będzie zarządzał w pełni relacją. Jedną z implementacji mogło by być utworzenie takiego schematu:

Zalet rozwiązania jest kilka, obca dla mnie tabela „order_item” nie ma żadnej wiedzy o związku z „moim” schematem (nie ma mojego ID), to ja w pełni zarządzam swoimi powiązaniami, łącznie z tym, że do mnie należy decyzja czy formalnie tworzyć relację bazodanową do obcej tabeli, czy robić to wyłącznie na poziomie aplikacyjnym. Separacja jest dużo większa, zmniejszają się zależności. Oczywiście dalej dane szczegółowe pozycji zamówienia przechowywane są w osobnej tabeli i musimy posiłkować się JOIN aby je odczytać z bazy lub szukać rozwiązań na poziomie aplikacyjnym. Analizując to rozwiązanie możemy dojść do wniosku, że zyskaliśmy niezależność, płacąc koszt w postaci wzrostu złożoności i jednak spadku wydajności (kolejna tabela do czytania).
Relacja w tablicy
Możemy zadać sobie pytanie, czy na pewno potrzebujemy osobnej tabeli tylko po to aby zapamiętać zestaw wartości identyfikatorów w tabeli obcej? Przeglądając dostępne typy kolumn w bazie Postgres znajdujemy typ tablicowy. Tablica jako wartość w kolumnie?! Dokładnie tak. Zakładając że możemy przechować w własnej kolumnie wiele ID z tabeli powiązanej nasz schemat upraszcza się do
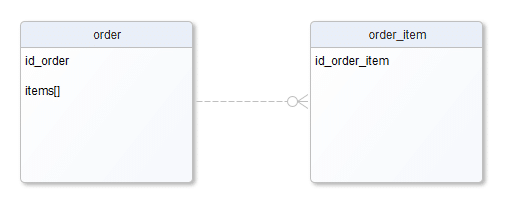
Wygląda dziwnie, ale jest to pseudo-relacja 1:N, „pseudo” dlatego, że formalnie nie ma założonych więzów integralności (foreign key). Co ważne, tabela „dziecka” nie ma wskazania na „rodzica”, bo to „rodzic” przechowuje tablicę wskazań na „dzieci”. Mamy kompletną separację, dostajemy to bardzo małym kosztem, zyskujemy na wydajności bo czytając jeden wiersz z tabeli „order” mamy komplet namiarów na wszystkie pasujące „order_items”. Wsparcie dla kolumn tablicowych w silnikach bazy danych nie jest powszechne, jednak silniki w rodzaju Postgres czy BigQuery posiadają doskonałe wsparcie dla tego typu danych. Na uwagę zasługuje funkcja UNNEST(), która wartość tablicową zamienia na wiersze, wiersze które możemy potem łączyć za pomocą JOIN tak jakby były one umieszczone w tabeli. Dodajmy jeszcze, że typ tablicowy może być wielowymiarowy, co pozwala przechowywać nie tylko listę identyfikatorów ale całe zbiory tabelarycznych wartości, które potem można traktować jako wielokolumnowe tabele.
XML, JSON
Wiemy już, że typem kolumny w tabeli nie musi być wyłącznie wartość prosta np. Varchar, czy Long, wiemy też, że możemy z powodzeniem przechowywać wartości tablicowe. Idąc dalej warto zauważyć, że niektóre silniki baz danych oferują ponadto typy bardziej złożone, np. XML czy JSON. Nasz model danych mógłby wyglądać tak:
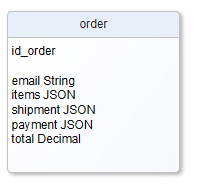
Zyskujemy zmniejszenie zależności i złożoności, poprawę wydajności. Jednym odczytam dostajemy wszystkie potrzebne dane. Sami panujemy nad ich strukturą. Od niczego nie zależymy. Co tracimy? Zależnie od wsparcia dostarczanego przez silniki baz danych możemy mieć mniej lub bardziej zaawansowaną obsługę formatów JSON czy XML. W przypadku zadań polegających np. na znalezieniu zamówień za które zapłacono BLIK’iem, a informacja ta jest zaszyta głęboko w JSON’ie, brak wsparcia w zakresie indeksowania JSON’a może być niemałym problemem. Oczywiście można to kompensować stosując np. indeks pełnotekstowy, czy dublując potrzebne informacje w kolumnach tabeli z indeksami na tych kolumnach, czy stosować dowolną inną formę wzorca „read model”. Wymaga to jednak dodatkowych działań i jest wadą takiego podejścia.
Baza dokumentowa
Baza dokumentowa to baza danych, która wyrosła z ostatniego opisanego wyżej podejścia. Główne założenie jest takie, że wszystkie dane dotyczące obiektu który nas interesuje składamy w jedną złożoną strukturę np. w JSON i zapisujemy jako komplet danych do bazy pod pewnym identyfikatorem. Nie ma JOIN, nie ma SQL, wielokrotnego odczytu z wielu tabel, jest szybko, łatwo, super skalowalnie. Oczywiście są też wady. Mamy ograniczone możliwości analizy danych, które zazwyczaj dostajemy wraz z SQL, tu nie ma SQL’a i to robi różnicę. Mamy także ograniczoną kontrolę nad strukturą, brak jednoznacznie zdefiniowanego schematu, tabel i relacji, uwalnia, daje swobodę ale i zmniejsza kontrolę. Pojawiają się także problemy przy generalnych zmianach schematu w obrębie jego fragmentów składowych, niestety każdy zbiór danych jest rozłączny i musi być dostosowany w odrębny sposób.
Jak widzimy możliwości jest wiele (na pewno więcej niż opisałem powyżej). Jak zawsze, odpowiedź na podstawowe pytanie, „czego użyć w danym przypadku” jest niezmienna „to zależy”. Warto znać różne rozwiązania, mieć świadomość kontekstu, wymagań, potrzeb czy „drajwerów” i ze świadomością wad i zalet wybrać najbardziej optymalne rozwiązanie.

Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania
Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania