


























Osoby zajmujące się bazami danych wcześniej lub później spotkają się z zagadnieniem blokad. Bywa to spotkanie na tyle kłopotliwe, że jak się wydaje — bez blokad się nie da, a same blokady powodują, że jest wolniej czyli gorzej. Większość nowoczesnych silników baz danych oferuje poziom izolacji transakcji „read committed” co powoduje, że wiersze zmodyfikowane w jednej transakcji nie mogą być modyfikowane jednocześnie przez inne transakcje, choć mogą być z powodzeniem czytane (i to jest piękne). Koszt tej wygody jest znaczący, mechanizm MVCC (Multiversion Concurrency Control), który to nam oferuje, w konsekwencji prawie zawsze powoduje konieczność okresowego „odśmiecania” baz danych z efektów ubocznych swojego działania, jakim są stare, niepotrzebne strony, co nie obywa się bez ujemnego wpływu na wydajność. Ponosimy koszty, ale w zamian mamy prostą zasadę:
zapis nie blokuje odczytu
Jednak z „read committed” wiąże się jeden mniej znany a dosyć przykry problem. Analizując operację wstawiania wierszy do bazy (INSERT), można uznać, że operacja taka nie jest w żaden sposób blokująca, bo niby jakie blokady mogłyby się zakładać i w jakim celu? Niestety w wielu przypadkach blokady jednak się zakładają, dzieje się tak np. w bazie danych POSTGRES. Rozważmy prosty, przykładowy schemat bazy danych:
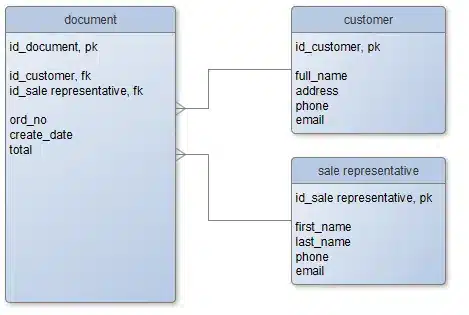
Ze względu na istnienie więzów integralności (foreign key), polecenie INSERT do tabeli „document” na czas trwania transakcji, w której obrębie będzie wywołane, spowoduje powstanie dwóch blokad typu „FOR KEY SHARE” każda z nich powstanie na odpowiednie wiersze w tabelach „customer” i „sale representative”:
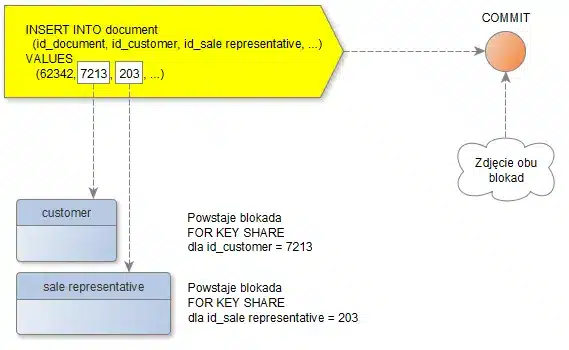
blokady „FOR KEY SHARE” nie są blokadami bardzo restrykcyjnymi, jednak konfliktują z blokadami typu „UPDATE” co powoduje pewne przykre konsekwencje:
- wskazane wiersze w tych dwóch tabelach nie będą mogły zostać poprawione, w tym sensie, że nie będą mogły zostać wykonane na nich polecenia UPDATE ani DELETE, będzie trzeba zaczekać na zakończenie naszej transakcji z INSERT,
- jeżeli któryś z tych wierszy z tabel „customer” lub „sale representative” jest już w trakcie poprawy lub usuwania, to nasze polecenie INSERT musi czekać na zakończenie transakcji, w której się to dzieje.
Jak bardzo zjawisko to może obniżyć współbieżność w bazie danych, jestem pewien, że tłumaczyć nie trzeba. W tym miejscu należy zadać pytanie, dlaczego tak się dzieje?
Silnik bazy zabezpiecza się przed tym, że podczas UPDATE może zostać zmieniona wartość w kolumnie klucza głównego („id_customer”, „id_sale representative”), co spowodowałoby naruszenie więzów klucza obcego. Jednak oczywisty jest fakt, że w 99% systemów, kolumn z kluczem głównym się nie zmienia, zmiana identyfikatora wiersza jest po prostu szkodliwa i nikomu nie potrzebna. Mamy zatem serwer z super zabezpieczeniem (obniżającym wydajność) przed sytuacją, która nie występuje!
Ku mojemu zdziwieniu i wielkiej radości, developerzy Postgres’a zauważyli ten problem i w wersji 9.3 sytuacja uległa znacznej poprawie, rozwiązanie jest proste, wprowadzono kolejny typ blokady „NO KEY UPDATE”, i teraz:
- polecenie UPDATE na kolumny poza kolumną klucza głównego powoduje zamiast blokady UPDATE nową blokadę „NO KEY UPDATE”,
- polecenie UPDATE na kolumny łącznie z kolumną klucza głównego powoduje tak jak wcześniej blokadę „UPDATE”,
- i uwaga:
blokada „FOR KEY SHARE” nie konfliktuje z
„NO KEY UPDATE”
Podsumowując, dzięki genialnie prostemu i po prostu genialnemu rozwiązaniu mamy mniej blokujące się operacje, z zachowaniem spójności więzów integralności. Lekko abstrahując od tematu, nadmienić trzeba także, że krótkie transakcje zapewniają krótkie czasy trwania dowolnych blokad i jako takie są zdecydowanie zalecaną, dobrą praktyką. Jako temat otwarty zostawiam rozważania, czy warto płacić wysoką, jakby nie było, cenę za posiadanie więzów integralności na poziomie bazy danych i w jakich sytuacjach można by z nich zrezygnować.

Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania
Krzysztof Olszewski
Dyrektor Technologii i Architektury Oprogramowania