


























Wyobraź sobie algorytmy, które uczą się jak ludzie… tylko zdecydowanie szybciej. Po kilku minutach treningu potrafią filtrować spam i grupować dokumenty. Tak działa machine learning – technologia sztucznej inteligencji stosowana już przez 90% firm z sektora MŚP*.
W tekście znajdziesz
- Czym jest uczenie maszynowe (machine learning)?
- Jak działa uczenie maszynowe?
- Rodzaje uczenia maszynowego
- Zastosowanie uczenia maszynowego
- W jakich branżach stosuje się algorytmy uczenia maszynowego
- Korzyści wynikające z uczenia maszynowego
- Wyzwania związane z uczeniem maszynowym
- Przyszłosć uczenia maszynowego

Czym jest uczenie maszynowe (machine learning)?
Uczenie maszynowe (ang. machine learning) jest metodą szkolenia systemów komputerowych, która polega na analizie dużych zbiorów danych. Algorytmy wyszukują w nich wzorce i korelacje i na tej podstawie podejmują określone decyzje. To tzw. modelowanie predykcyjne, które jest obecnie stosowane w wielu branżach, od medycyny po handel detaliczny. Co więcej, pomaga podczas codziennych czynności, np. pisania wiadomości na Messengerze (automatyczne podpowiedzi).
Początki uczenia maszynowego
Początki uczenia maszynowego sięgają lat 50. XX wieku. Wówczas Alan Turing stworzył teoretyczne podstawy tej dziedziny. Efektem pracy była publikacja Computer Machinery and Intelligence. 2 lata później Artur Samuel stworzył maszynę do gry w warcaby. Wtedy także zdefiniował pojęcie uczenia maszynowego jako zdolność komputerów do nauki bez wcześniejszego programowania.
Jak uczenie maszynowe wiąże się z AI?
Sztuczna Inteligencja (ang. Artificial Intelligence) oznacza zdolność systemów komputerowych do wykonywania zadań mentalnych tradycyjnie zarezerwowanych dla człowieka (wnioskowanie, planowanie, krytyczne myślenie itd.). Aby to osiągnąć, programy uczą się i stopniowo zaczynają symulować procesy ludzkiego myślenia. Jedną z metod, która to umożliwia, jest uczenie maszynowe.
Uczenie maszynowe a głębokie – co je różni?
Uczenie głębokie (ang. Deep Learning) jest rodzajem uczenia maszynowego (ang. Machine Learning), które opiera się na sztucznych sieciach neuronowych (ang. Neural Networks), symulujących działanie ludzkiego mózgu. Dzięki wielowarstwowej strukturze Deep Learning przewyższa Machine Learning w rozwiązywaniu złożonych zadań, np. precyzyjnym rozpoznawaniu mowy czy analizie zdjęć, grafik itd.
Jak działa uczenie maszynowe?
W uczeniu maszynowym kluczową rolę odgrywa analiza danych. Zamiast programować każdą regułę, twórcy i użytkownicy wprowadzają do modelu odpowiednie informacje. Następnie narzędzie przekopuje zbiór, identyfikując wzorce i zależności występujące między danymi, co umożliwia tworzenie nowych pojęć oraz ciągły rozwój.
Wyjaśniamy to krok po kroku:
- Zbieranie i przygotowywanie danych (ang. input data) – na początku należy zebrać wysokiej jakości dane (np. zdjęcia, teksty, wyciągi z transakcji bankowych itd.) potrzebne do nauczenia określonej reakcji. W kolejnym etapie podlegają one czyszczeniu (usuwanie błędów), są też oznaczane i klasyfikowane (np. opisuje się obiekty na zdjęciach, wyjaśnia znaczenie słów itd.).
- Trenowanie modelu (ang. develop model) – algorytmy analizują materiał i kalibrują wewnętrzne parametry, tak aby uzyskać rezultat pożądany przez twórców. Dużą rolę odgrywa tu tzw. Funkcja Kosztu określająca poziom kary za nieprecyzyjne prognozy. Dzięki rozwiązaniu system dokonuje autokorekt i uzyskuje z czasem coraz lepsze wyniki.
- Weryfikacja modelu (ang. test) – po szkoleniu weryfikuje się rezultaty przy pomocy zestawu walidacyjnego, m.in. danych testowych. Celem tego kroku jest wychwycenie błędów.
- Analiza i interpretacja wyników (ang. analyze) – analiza wyników pozwala oceniać poziom wytrenowania algorytmów. Na przykład jeśli model uczył się rozpoznawać cyfry, przyswajając cechy każdego znaku, to rola człowieka polega na sprawdzaniu, czy kształty i proporcję linii są odpowiednie.
Rodzaje uczenia maszynowego
Proces uczenia maszynowego można podzielić na cztery podstawowe rodzaje:
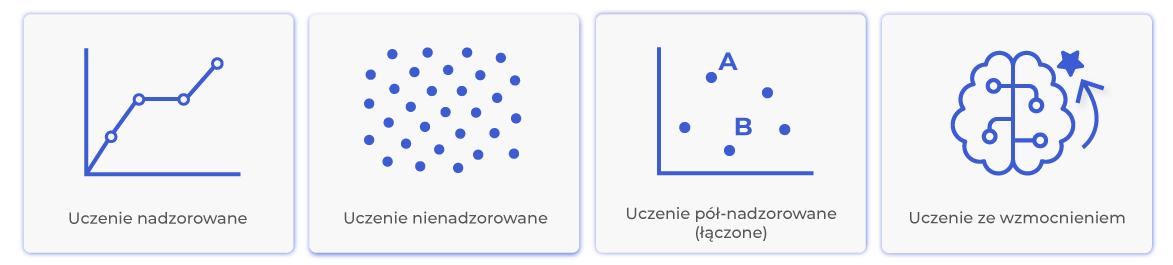

Uczenie nadzorowane
W uczeniu nadzorowanym model uczy się na danych oznaczonych. W każdej puli danych znana jest prawidłowa odpowiedź. Przykład to algorytm analizujący samochody, który ma odróżnić vana od kombi. Dane wejściowe zawierają zdjęcia i specyfikę dwóch typów pojazdów, ale wyłącznie jeden to tzw. wartość dodana, czyli oczekiwany rezultat. Model rozpoznaje podobieństwa i różnice tak długo, aż w końcu uzyskuje poprawny wynik.

Uczenie nienadzorowane
W uczeniu nienadzorowanym algorytmy analizują dane nieoznaczone. Działają jak człowiek, który intuicyjnie poznaje świat, lecz wciąż brak mu gotowych odpowiedzi. W ten sposób często trenowane są systemy pomocne w grupowaniu obiektów (clustering), np. klasyfikowaniu dokumentów wg tematów czy klientów według nawyków zakupowych.

Uczenie pół-nadzorowane (łączone)
Uczenie pół-nadzorowane polega na połączenie obu metod. Algorytmy korzystają z niewielkiej ilości danych oznaczonych i dużej ilości nieoznaczonych. Te pierwsze mają wprawić cały proces w ruch, wskazać zasadę działania i przyspieszyć analizę informacji.
Tego typu trening jest stosowany wtedy, kiedy brakuje środków i zasobów na etykietowanie wszystkich danych.

Uczenie ze wzmocnieniem
Podczas uczenia ze wzmocnieniem system dysponuje określoną pulą reakcji. Uczy się poprzez interakcję ze światem zewnętrznym, otrzymując nagrody za dobre decyzje. W ten sposób model wie, które z nich pozwalają wykonać dane zadanie.
Taką technikę często stosuje się w grach video. W końcu lepiej pozwolić modelowi działać i w toku pracy oceniać każde jego zachowanie, niż uczyć wszystkich ruchów, które można wykonać np. podczas gry w szachy.
Zastosowanie uczenia maszynowego
Uczenie maszynowe sprawdza się w wielu zadaniach. Oto kilka konkretów:
- Rozpoznawanie obrazów: systemy rozpoznają twarze czy identyfikują obiekty na zdjęciach.
- Przetwarzanie Języka Naturalnego (NLP): algorytmy tłumaczą teksty, analizują ton emocjonalny postów w mediach społecznościowych i rozmawiają z użytkownikami (tak działają np. chatboty).
- Prowadzenie autonomicznych pojazdów: uczenie maszynowe służy tu do analizy danych przechwytywanych przez systemy pojazdów (wbudowane czujniki i radary) i uczy system wykrywać obiekty na drodze.
- Systemy rekomendacji: stosowany w branży e-commerce. Sugeruje produkty, filmy (Netflix) lub usługi zgodne z preferencjami użytkowników.
- Diagnoza medyczna: wykorzystanie algorytmów do diagnozy chorób, analizy obrazów medycznych czy tworzenia precyzyjnych programów leczenia.
- Analiza finansowa: modele pomagają w wykrywaniu oszustw, badają ryzyko finansowe i przewidują zmiany na rynku. Właściwie wytrenowany model może np. prześledzić historię podatkową danego klienta, zwracając uwagę na określone odpisy od podatku.
W jakich branżach stosuje się algorytmy uczenia maszynowego?
Branża produkcyjna
Uczenie maszynowe jest szeroko stosowane w firmach produkcyjnych. Przewiduje awarię maszyn, monitoruje poziom zużycia materiałów czy automatyzuje składanie zamówień do dostawców. Sprawdza się również w procesie planowania oraz harmonogramowania produkcji. W tym przypadku inteligentne algorytmy opracowują zintegrowane plany oraz optymalnie rozkładają realizację poszczególnych zleceń w czasie.
Handel nowoczesny (e-commerce, retail)
W e-commerce czy retail algorytmy uczenia maszynowego ułatwiają personalizację doświadczeń klientów. Na podstawie tysięcy danych analizują preferencje zakupowe użytkowników, aby rekomendować produkty zgodne z ich gustem. Ponadto pomagają marketingowcom m.in. w pisaniu opisów produktów, kategorii, ofert oraz innych materiałów promocyjnych i reklamowych.
Energetyka
W branży energetycznej uczenie maszynowe służy do kontrolowania zużycia energii, wspiera również kierownictwo w zarządzaniu pracą w rozproszonych sieciach. W efekcie minimalizuje to koszty i zwiększa efektywność systemów energetycznych.
Korzyści wynikające z uczenia maszynowego
Wdrożenie w firmie uczenia maszynowego przekłada się na szereg korzyści, m.in.:
- Minimalizacja kosztów – automatyzacja minimalizuje czas operacji, obniżając tym samym wydatki.
- Zwiększenie satysfakcji klientów –algorytmy uczenia maszynowego mogą personalizować doświadczenia klientów i tym samym wpływać pozytywnie na poziom zadowolenia z usługi.
- Wzrost trafności podejmowanych decyzji – algorytmy uczenia maszynowego mogą identyfikować zmiany (np. popytu) oraz przewidywać przyszłe potrzeby (np. klientów). Zwiększa to trafność decyzji biznesowych.
- Wzrost bezpieczeństwa – uczenie maszynowe przyspiesza wykrywanie oszustw finansowych lub wirusów w programach czy aplikacjach. W narzędziach antyspamowych może weryfikować wiadomości i oznaczać podejrzane oferty etykietą niechciana korespondencja. Przekłada się to na wysoki poziom bezpieczeństwa.
Wyzwania związane z uczeniem maszynowym
Uczenie maszynowe stawia przed użytkownikami również szereg wyzwań. Pierwsze – jakość danych. Jeśli te zawierają uprzedzenia, niezweryfikowane informacje, np. powielają teorię spiskową o celowym rozprzestrzenieniu Covid-19, model może je replikować w każdym wyniku.
Poza dezinformacją wyzwaniem jest również przetrenowanie. Dochodzi do tego, kiedy model tak precyzyjnie dostraja się do danych treningowych, że traci umiejętność uogólniania i skutecznego działania w nowych warunkach. To tak jakby człowiek, który przeanalizował tysiące przykładów operacji matematycznych, np. sumowania, zamiast zrozumieć regułę, wykuł działania na pamięć.
Warto wspomnieć też o tzw. modelu czarnej skrzynki. Co to znaczy? Uczenie maszynowe często generuje wyniki, które trudno wyjaśnić. A w końcu w diagnozie nawet dobrze rozpoznanych chorób, takich jak przeziębienie, dużą rolę odgrywa każdy drobny czynnik.
Aby temu zapobiegać twórcy i badacze uczenia maszynowego przyjęli kilka zasad:
- wynik operacji algorytmów zawsze musi oceniać człowiek
- każdy system powinien potrafić wyjaśnić, jak uzyskał określoną odpowiedź (krok po kroku)
- proces powinien być zrozumiały dla człowieka
Przyszłość uczenia maszynowego
Uczenie maszynowe ułatwia wykonywanie wielu codziennych czynności. Algorytmy pomagają w wyszukiwaniu produktów w sklepach online, grają z ludźmi w gry wideo, czy też doradzają w aplikacjach do planowania podróży. Skala możliwych zastosowań stale się zwiększa.
Aktualnie badacze rozwijają uczenie transferowe czy meta-uczenie. Proces doskonalenia algorytmów wiąże się jednak z pytaniami etycznymi, w tym jednym z ważniejszych – jak zapewnić transparentność algorytmów? Wyzwaniem przyszłości będzie prawna regulacja tych mechanizmów, która nadąży za tempem rozwoju technologii.