


























Duże modele językowe (ang. LLM – Large Language Models) są jednym z najważniejszych osiągnięć w dziedzinie sztucznej inteligencji (AI). Przyspieszają tworzenie tekstów, analizują dokumenty i… obsługują klientów. Ich potencjał wzrasta z roku na rok.
Jak działają? Jak są zbudowane? Jak z nich korzystać z LLM, aby czerpać najwięcej korzyści? Szczegółowo wyjaśniamy.

Co to jest LLM?
Skrót LLM oznacza Large Language Model, czyli duże modele językowe. Są to nowoczesne systemy sztucznej inteligencji (AI), które reagują na polecenia wydawane w języku naturalnym i wykonują różnorodne operacje na tekstach: skracają, indeksują, analizują, tłumaczą itp.
Architektura LLM – jak zbudowane są duże modele językowe ?
LLM opierają się na tzw. architekturze transformatorów – zaawansowanych algorytmach, które sekwencyjnie przetwarzają informacje z wielu źródeł. Pomaga im w tym tzw. mechanizm uwagi (który podobnie jak ludzki mózg – selekcjonuje najważniejsze informacje). Transformatory są złożone z koderów i dekoderów. Pierwsze tworzą warstwę wejściową, pobierają surowe dane i przekazują w głąb ukrytych poziomów modelu. Drugie generują wynik, np. gotowy artykuł czy odpowiedź na pytanie klienta.
Jak trenowane są LLM?
Trening dużych modeli językowych uwzględnia zazwyczaj 2 etapy:
Etap 1: bazowe szkolenie dużych modeli językowych
Podczas podstawowego treningu modele LLM przetwarzają ogromne ilości danych (np. GPT-4 wytrenowano na 175 miliardach przykładów). Selekcja informacji ma tu małe znaczenie, pamięć zasilana jest różnorodnymi treściami, w tym książkami oraz tekstami prasowymi czy internetowymi (z naciskiem na te ostatnie). Następnie model analizuje materiał, wyszukując ogólne wzorce i reguły łączenia słów, zdań, akapitów itd.
Etap 2: specjalizacja
LLM mogą być dodatkowo dostosowywane do potrzeb konkretnych branż. W tym celu wykorzystuje się dwie metody:
- Fine-tuning – proces dodatkowego treningu. Polega na budowaniu bazy wiedzy dot. określonego tematu. Zapleczem treningowym mogą być np. informacje medyczne, które w przyszłości umożliwią dokładniejszą diagnozę choroby. Fine-tuning pozwala więc dostrajać model LLM, aby lepiej wpisywał się w potrzeby użytkowników o konkretnych zadaniach.
- Prompt-tuning – czyli sterowanie sposobem formułowania zapytań. Tak można uzyskać dokładniejsze odpowiedzi, jednocześnie pomijając czasochłonny trening. Na przykład zamiast zapytać model „Jak wdrożyć system ERP?”, warto doprecyzować pytanie: „Jak wdrożyć system ERP w branży X ?”. Nawet tak niewielkie zmiany zwiększają trafność wyników.
Główne rodzaje LLM
Wyróżnia się trzy rodzaje modelów LLM:
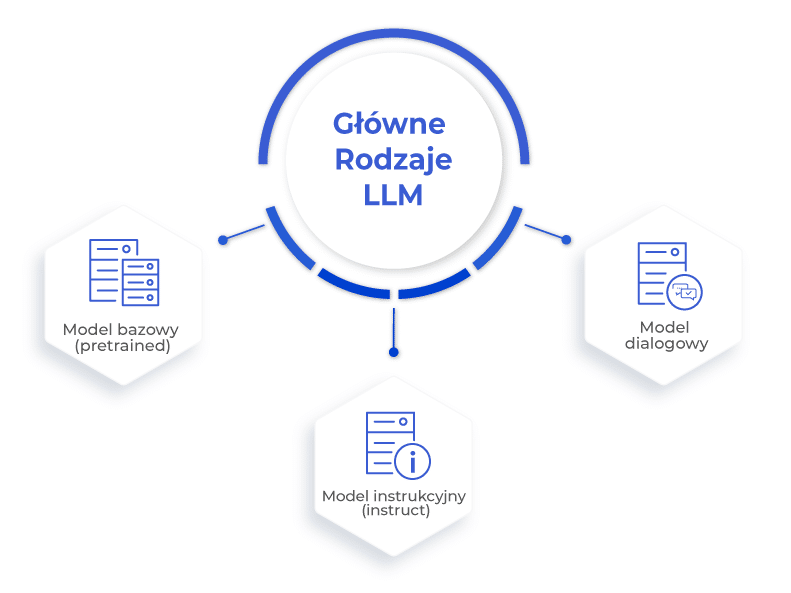

Model bazowy (pretrained)
Model bazowy jest najpopularniejszym rodzajem oprogramowania LLM – wytrenowany na dużej ilości różnorodnych danych (głównie internetowych). Z jednej strony ma sporo wiedzy ogólnej, z drugiej wciąż brakuje mu specjalizacji potrzebnej do wykonywania określonych zadań branżowych. Mechanizm modelu przewiduje następne słowo, bazując na wcześniej rozpoznanym kontekście. Tak uczy się podstawowych reguł rządzących komunikacją językową, co pozwala mu np. sprawnie generować, podsumowywać i tłumaczyć proste treści.

Model instrukcyjny (instruct)
Model instrukcyjny to LLM po fine – tuning, dostosowany do realizacji wyraźnie zdefiniowanych zadań. Dokładnie odczytuje polecenia zawarte w prompcie, zwracając większą uwagę na kontekst i intencję użytkownika. Dzięki temu lepiej niż jego uniwersalny brat wykonuje złożone operacje wymagające precyzji, np. tłumaczenia specjalistyczne czy programowanie.

Model dialogowy
Model dialogowy jest rozwinięciem modelu instrukcyjnego. Został opracowany z myślą o naturalnej konwersacji z użytkownikiem. Aktywnie reaguje na polecenia, aby dostarczyć odpowiedzi najbardziej zgodnych z intencją pytającego. Pomaga mu w tym zdolność do analizy kontekstu i pełnej historii rozmowy.
Czym różni się od modelu instrukcyjnego? Po otrzymaniu polecenia, np. wygeneruj 100 sloganów reklamowych promujących najnowszy produkt firmy, model instrukcyjny dostarczy dokładnie 100 propozycji. Konwersacyjny zrobi to samo, lecz po wszystkim zapyta, czy interesują nas kolejne, ewentualnie poda wskazówki ułatwiające napisanie własnych propozycji! Interaktywnie i praktycznie.
LLM i przetwarzanie języka naturalnego w praktyce
Dzięki funkcji przetwarzania języka naturalnego LLM mogą wykonywać wiele przydatnych operacji na tekście:
- Automatyczne tłumaczenia.
- Streszczanie dokumentów.
- Generowanie treści, m.in. artykułów czy opisów produktów.
- Indeksowanie i przeszukiwanie dużych wolumenów tekstów.
- Analiza sentymentu: wykrywanie emocji zawartych w tekstach.
- Pogłębiony reasearch: wykrywanie zarówno cech stylu (słowa, frazy itd.), jak i weryfikacja zawartości merytorycznej.
Sprawia to, że duże modele językowe sprawdzają się w wielu branżach:
- Ochrona zdrowia – personalizacja planów leczenia i analiza historii choroby.
- Rozwój oprogramowania – automatyczne tworzenie instrukcji technicznych i generowanie szczegółowych opisów funkcji.
- Wsparcie działu HR – analiza CV i rekomendowanie kandydatów.
- Retail i e-commerce – m.in. generowanie opisów produktów oraz prostych komunikatów kierowanych do klientów (np. dot. promocji).
- Prawo – generowanie m.in. ekspertyz, umów czy aneksów.
- Marketing – analiza preferencji klienta czy redagowanie tekstów blogowych, opisów produktów, landing page itd.
Przykłady popularnych dużych modeli językowych
Poniżej wymieniamy najpopularniejsze modele językowe LLM:
GPT - 3/GPT - 4
Model językowy GPT-3 (Generative Pretrained Transformer 3). Rozwiązanie stworzone przez OpenAI jest obecnie jednym z najbardziej zaawansowanych modeli językowych na świecie. Dobrze radzi sobie z postami na media społecznościowe, pisaniem rozbudowanych artykułów czy tłumaczeniem tekstów. Słabszy w pozyskiwaniu wartościowych informacji, zwłaszcza kiedy wymaga to analizowania kilku wątków jednocześnie.
BERT
BERT (Bidirectional Encoder Representations from Transformers) opracowany przez Google w 2018 roku. Kluczowe funkcje narzędzia to analiza sentymentu (wykrywanie tonu emocjonalnego wypowiedzi), rozpoznawanie nazw własnych (imion, miejsc, tytułów itp.). Sprawdza się w ekstrakcji informacji, np. z dokumentów medycznych, streszczaniu tekstów oraz obsłudze klienta. Jest często wdrażany w asystentach głosowych.
Główną barierą w implementacji stanowią wymagania sprzętowe. Ponieważ BERT ma złożoną architekturę, to do sprawnego działania potrzebuje procesorów z dużą mocą obliczeniową oraz sporych zasobów pamięci RAM, co wymaga znacznych środków finansowych.
XLM-R
XLM – R (Cross-lingual Language Model – RoBERTa) został stworzony przez Facebook AI Researcher w 2019 roku. Do budowy narzędzia wykorzystano autorską architekturę RoBERTa, następnie nakarmiono model tekstami pochodzącymi z różnych języków (około 100). Dzięki temu XLM – R dobrze radzi sobie z tłumaczeniami maszynowymi, ekstrakcją informacji i analizą sentymentu.
Warto podkreślić, że wprowadzenie na rynek XLM – R było jednym z ważniejszych kroków w rozwoju modeli wielojęzycznych.
Przyszłość i rozwój dużych modeli językowych
Technologia dużych modeli językowych cały czas ewoluuje. Rosnący potencjał technologii idzie w parze z rosnącą wartością, która wg Valuates Reports osiągnie ponad 40 bilionów w roku 2029.*
Cały czas wzrasta również potencjalna skala biznesowych zastosowań technologii. Proste teksty zastępują rozbudowane merytoryczne treści, skrótowe odpowiedzi – pełna rozmowa z klientem..